Исследование алгоритмов нечеткой кластеризации
Лабораторная работа №2.
Введение
При предварительной обработке данных важным этапом является выделение похожих данных в группы, или кластеризация, и поиск центров этих кластеров, то есть точек, около которых группируются экспериментальные данные. Выявление подобных центров позволяет сопоставить с этими центрами функции принадлежности переменных при последующем проектировании системы нечеткого вывода.
Для поиска центров кластеров используются различные алгоритмы кластеризации. В данной лабораторной работе будет разработана модель для исследования алгоритмов нечеткой кластеризации, таких как алгоритм нечетких С-средних и алгоритм субтрактивной кластеризации.
Цель работы
- Приобрести первичные навыки для проведения кластерного анализа в SimInTech
Задачи работы
- Изучить особенности различных алгоритмов нечеткой кластеризации
- Разработать модель на базе библиотеки Нечеткая логика для проведения кластерного анализа
- Построить диаграммы рассеяния, отображающие положение точек и центров кластеров для двух алгоритмов нечеткой кластеризации
- Сравнить значения координат центров кластеров, найденных с помощью каждого из алгоритмов
- Исследовать влияние параметров кластеризации на положение центров кластеров.
Основные теоретические сведения
Кластеризация, или кластерный анализ – это задача разбиения множества объектов на группы, называемых кластерами. В результате кластеризации внутри каждой группы должны оказаться схожие объекты, а объекты разных групп должны быть как можно более различны. В метрическом пространстве схожесть объектов обычно определяется через расстояние, причем расстояние может рассчитываться как между объектами, так и между потенциальными центрами кластеров и объектами: чем меньше расстояние, тем объекты более схожи. Чаще всего координаты центров кластеров заранее неизвестны и находятся в процессе разбиения данных на кластеры.
- Отбор выборки объектов для кластеризации
- Определение множества переменных, по которым будут оцениваться объекты в выборке
- Вычисление значений меры сходства между объектами
- Применение метода кластерного анализа для создания групп сходных объектов (кластеров)
- Представление результатов анализа
- Четкие, или непересекающиеся, алгоритмы. Исходное множество объектов разбивается на несколько непересекающихся кластеров, при этом каждый объект принадлежит только одному кластеру. При четкой кластеризации каждому объекту исходного множества ставится в соответствие кластер, к которому он принадлежит
- Нечеткие, или пересекающиеся, алгоритмы. Исходное множество объектов разбивается на несколько пересекающихся кластеров, при этом каждый объект может принадлежать нескольким или всем кластерам с различной степенью принадлежности. При нечеткой кластеризации каждому объекту исходного множества ставится в соответствие набор вещественных значений, показывающих степень принадлежности объекта к кластерам
Например, если при нечеткой кластеризации объект A относится к кластеру K1 со степенью принадлежности 0.9, к кластеру K2 – со степенью 0.04 и к кластеру К3 – со степенью 0.06, то при четкой кластеризации объект А будет отнесен к кластеру K1.
- Если известно количество кластеров, на которые следует разбить множество объектов, то для поиска центров кластеров используется алгоритм нечетких С-средних. При этом найденные центры кластеров могут не совпадать ни с одним объектом исходного множества
- При отсутствии информации о количестве кластеров возможно оценить количество кластеров визуально по диаграмме рассеяния – графическому отображению пар (x, y) исходных данных в виде множества точек на координатной плоскости. Если количество кластеров априорно неизвестно и произвести визуальную оценку затруднительно, то для определения количества кластеров и нахождения центров этих кластеров используется субтрактивная кластеризация. При этом поиск центров кластеров осуществляется среди точек исходного множества, то есть найденные центры кластеров совпадают с какими-либо объектами исходного множества, как следствие такие центры не соответствуют точным расположениям центров кластеров, а только обозначают их примерное расположение. После определения количества кластеров и их примерного расположения возможно уточнение значений координат центров кластеров с помощью алгоритма нечетких С-средних
Подробное описание алгоритма нечетких С-средних и субтрактивной кластеризации представлено на странице справочной информации для блока Нечеткая кластеризация библиотеки Нечеткая логика.
Описание метода генерации входных данных для кластеризации
- Для кластеризации необходимы пары чисел, поэтому будут сгенерированы пары случайных выборок одинаковой размерности, одна выборка из пары будет содержать значения координат точек по оси абсцисс, вторая – по оси ординат
- Исследование алгоритмов кластеризации необходимо провести на множествах точек, для
одного из которых известно количество кластеров, или его можно оценить визуально, а для
второго – количество кластеров неизвестно и невозможно оценить визуально, поэтому выборки
будут сгенерированы таким образом, чтобы по отображению полученного множества точек на
диаграмме рассеяния в первом случае можно было определить количество кластеров, а во
втором – нет. Для задания точек, рядом с которыми будут концентрироваться другие точки
множества, то есть для предопределения центров кластеров, необходима возможность задания
математического ожидания (МО) в функции генерации случайных чисел. Для управления
разбросом точек относительно заданного МО необходима возможность задания
среднеквадратического отклонения (СКО) в функции генерации случайных чисел, что необходимо
для генерации выборок двух типов:
- выборки, в которой разброс точек мал (СКО мало) и визуально легко определить количество кластеров, например, по первому рисунку (Рисунок 1, а) очевидно, что множество точек разбивается на три кластера
- выборки, разброс точек в которой велик (СКО велико) и визуально определить количество кластеров невозможно (Рисунок 1, б)
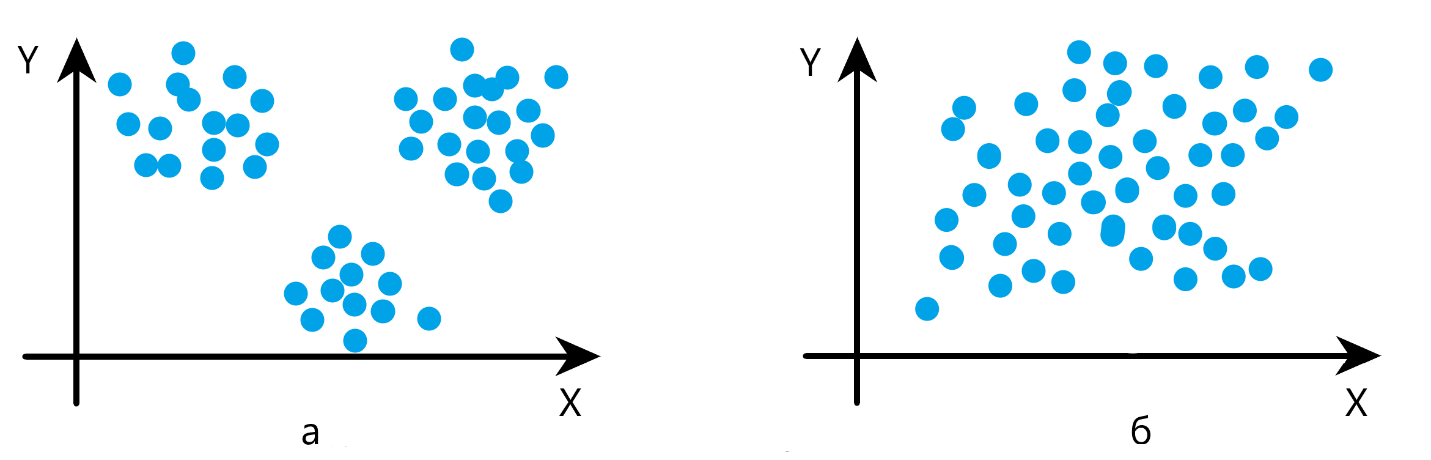
Для генерации множеств, качественно похожих на представленные на рисунке (Рисунок 1), для каждого случая будет сгенерировано по три пары выборок, для каждой пары будет задан свой центр, определяемый МО. Выборки для первого и второго случая будут иметь разные СКО для задания необходимого разброса точек на плоскости. Выборки будут генерироваться с помощью функции языка программирования – функции генерации Гауссовского шума с возможностью задания математического ожидания и среднеквадратического отклонения.
Выполнение лабораторной работы
- сгенерировать входные данные для кластеризации
- разработать модель для проведения кластерного анализа на сгенерированных данных
- построить диаграммы рассеяния для разных алгоритмов кластеризации
- сравнить полученные диаграммы рассеяния
Генерация входных данных для кластеризации
Чтобы исследовать алгоритмы нечеткой кластеризации, необходимо подготовить входные данные для кластеризации согласно методике, описанной выше. На первом этапе необходимо сгенерировать выборки таким образом, чтобы по отображению полученного множества точек на диаграмме рассеяния было легко оценить количество кластеров, на которое следует разбивать данное множество, то есть необходимо, чтобы точки были сконцентрированы около центров кластеризации и было мало точек, которые бы находились между кластерами. Таким образом, при генерации необходимо задать СКО достаточно малым.
- В главном окне SimInTech нажать левой кнопкой мыши на кнопку Файл и выбрать пункт Новый проект
- В выпадающем меню выбрать пункт Схема модели общего вида
- 1 блок Язык программирования из вкладки Динамические – с помощью данного блока будут сгенерированы случайные выборки
- 1 блок График Y от X из вкладки Вывод данных – с помощью данного блока будет производиться графическое отображение диаграммы рассеяния
Сохранить проект под именем "Генерация выборок.prt".
var x_1: array = 100#0, y_1: array = 100#0,
x_2: array = 100#0, y_2: array = 100#0,
x_3: array = 100#0, y_3: array = 100#0;
output x: array = 300#0, y: array = 300#0;
initialization
{заполнение массивов случайными числами с распределением Гаусса c
заданными математическим ожиданием среднеквадратическим отклонением}
for(i=1, 100)
begin
x_1[i] = randg(0.2, 0.1);
y_1[i] = randg(0.6, 0.1);
x_2[i] = randg(0.6, 0.1);
y_2[i] = randg(0.15, 0.1);
x_3[i] = randg(0.75, 0.1);
y_3[i] = randg(0.8, 0.1);
end;
// формирование выходных массивов
x = x_1 & x_2 & x_3;
y = y_1 & y_2 & y_3;
//заполнение матрицы значениями координат точек
M_data = [x, y];
// сохранение матрицы в файл в виде таблицы
savetab(M_data, "data_1.dat");
end;randg
генерируются шесть выборок, содержащих по 100 случайных чисел, принадлежащих распределению
Гаусса с указанными в аргументах функции МО и СКО, полученные выборки объединяются с помощью
оператора & для формирования выходных массивов x и
y с координатами точек полученного множества. С помощью функции
savetab координаты точек этого множества сохраняются в файл
data_1.dat в виде таблицы: в первый столбец записываются координаты по
оси абсцисс, во второй – по оси ординат.initialization ... end, чтобы генерация выборок
производилась только один раз при инициализации и только один раз они были записаны в файл
data_1.dat, иначе массивы будут заполняться случайными числами на каждом
расчетном шаге и перезаписываться в файл.
- Открыть окно Свойства графика блока График Y от X и на вкладке
Графики и оси отключить отображение линии графика и задать вид отображения
точек на графике согласно рисунку (Рисунок 5).
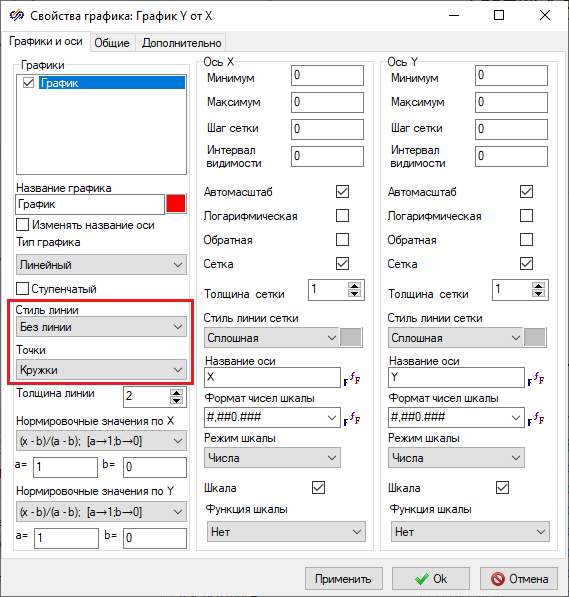
Рисунок 4. Окно "Свойства графика" блока "График Y от X" с выделенными свойствами, которые необходимо изменить. - На вкладке Общие в поле "Заголовок" изменить название графика на
"Диаграмма рассеяния" и отключить свойство "Показывать легенду" (Рисунок 6).
Рисунок 5. Окно "Свойства графика" блока "График Y от X", вкладка "Общие", с выделенным свойством, которое необходимо изменить. - На вкладке Дополнительно увеличить значение свойства "Максимальное
количество меток графика" в соответствии с заданной в скрипте блока Язык программирования размерностью выходных массивов (Рисунок 7).
Рисунок 6. Окно "Свойства графика" блока "График Y от X", вкладка "Дополнительно", с выделенным свойством, которое необходимо изменить.
Сохранить изменения и закрыть окно нажатием кнопки Ok.
После настройки схемы для генерации выборок, записи полученного множества точек в файл и построения диаграммы рассеяния этого множества необходимо запустить процесс моделирования и дождаться окончания расчета. При этом в директории с текущим проектом будет создан файл "data_1.dat", содержащий таблицу координат сгенерированного множества точек.
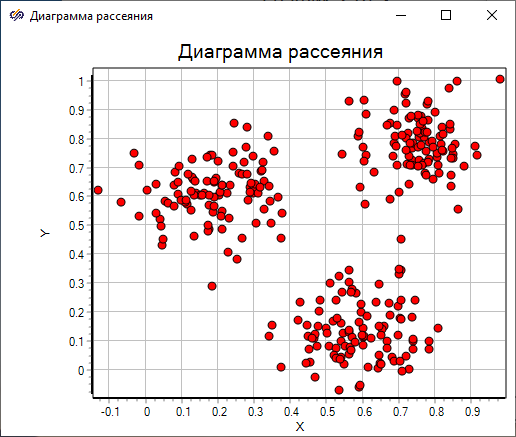
Полученная диаграмма рассеяния показывает, что для данного множества точек предопределенное значение количества кластеров и визуальная оценка количества кластеров совпадают и равны трем.
Генерация выборок для случая, когда количество кластеров можно оценить визуально, завершена.
Далее необходимо сгенерировать выборки таким образом, чтобы по отображению полученного множества точек на диаграмме рассеяния было невозможно оценить количество кластеров, на которое следует разбивать данное множество, то есть необходимо, чтобы точки располагались не исключительно около центров кластеризации, но и между кластерами. Таким образом, чтобы разброс точек относительного математического ожидания был большим, необходимо задать среднеквадратические отклонения достаточно большими.
...
for(i=1, 100)
begin
x_1[i] = randg(0.2, 0.25);
y_1[i] = randg(0.6, 0.3);
x_2[i] = randg(0.6, 0.25);
y_2[i] = randg(0.15, 0.3);
x_3[i] = randg(0.75, 0.25);
y_3[i] = randg(0.8, 0.3);
end;
...
// сохранение матрицы в файл в виде таблицы
savetab(M_data, "data_2.dat");
end;После изменения скрипта для генерации выборок, записи полученного множества точек в файл и построения диаграммы рассеяния этого множества необходимо запустить процесс моделирования и дождаться окончания расчета. При этом в директории с текущим проектом будет создан файл "data_2.dat", содержащий таблицу с координатами сгенерированного множества точек.
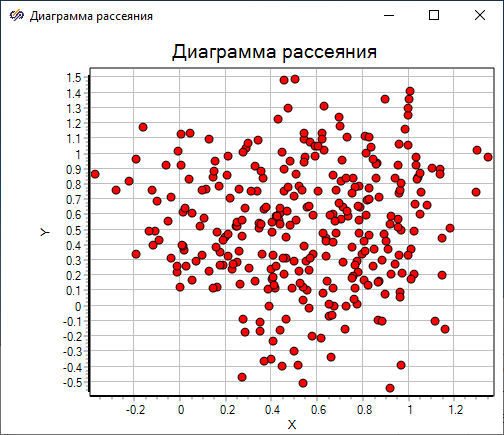
Полученная диаграмма рассеяния показывает, что для данного множества точек невозможно визуально оценить количество кластеров вследствие большого разброса точек относительно потенциальных центров – заданных математических ожиданий, и смешения точек разных кластеров.
Генерация выборок для случая, когда количество кластеров нельзя оценить визуально, завершена, требуется сохранить проект.
Разработка модели для проведения кластерного анализа при наличии информации о количестве кластеров
После подготовки данных для проведения кластерного анализа необходимо создать новый проект Схема модели общего вида и сохранить под именем "Нечеткая кластеризация.prt".

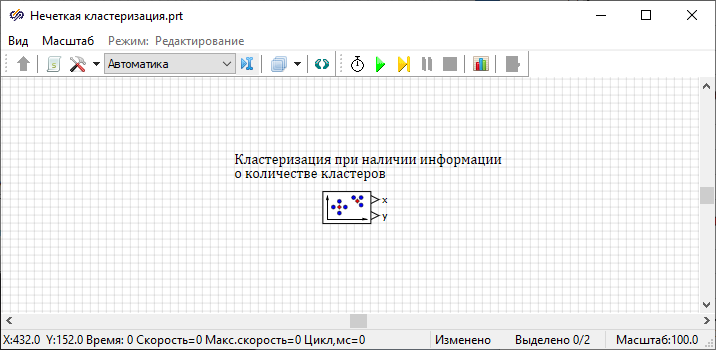
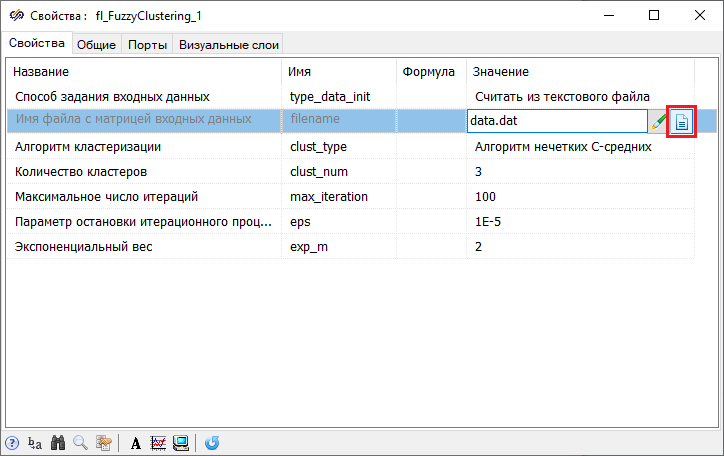
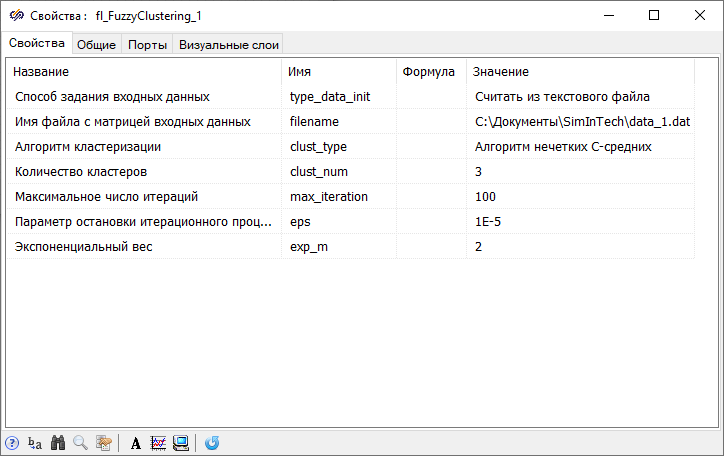
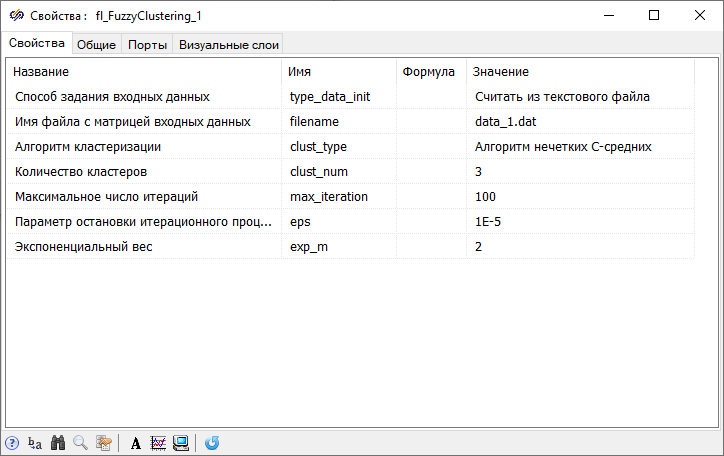
- Двойным нажатием левой кнопки мыши по блоку Нечеткая кластеризация вызвать
окно График Y от X, после чего необходимо открыть окно Свойства графика и на вкладке Графики и оси в колонках "Ось X" и "Ось
Y" задать значения свойств "Шаг сетки" равными "0.1" согласно
рисунку (Рисунок
21).
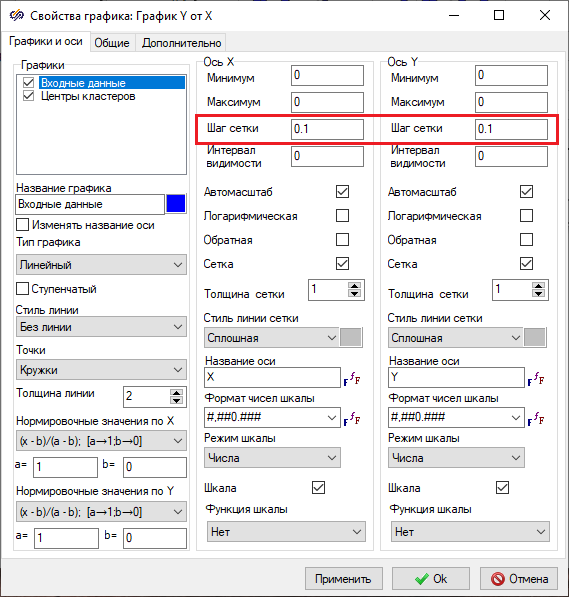
Рисунок 19. Окно "Свойства графика" блока "Нечеткая кластеризация" с выделенными свойствами, которое необходимо изменить. - На вкладке Общие задать название графика как "Кластеризация при наличии информации о количестве кластеров"
Сохранить изменения и закрыть окно нажатием кнопки Ok.
Запуск моделирования и построение графиков
После задания свойств для построения диаграммы рассеяния необходимо запустить процесс моделирования и дождаться окончания расчета.
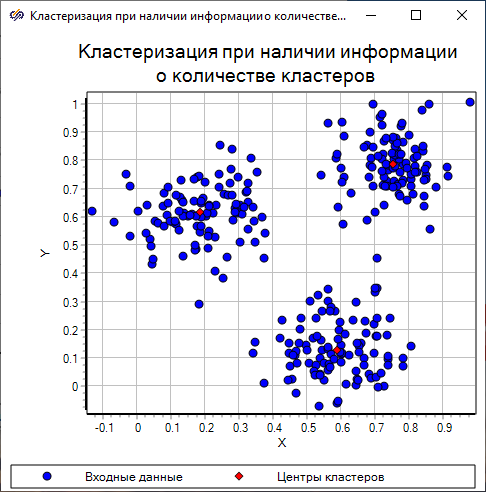
По полученной диаграмме рассеяния видно, что центры кластеров найдены правильно.
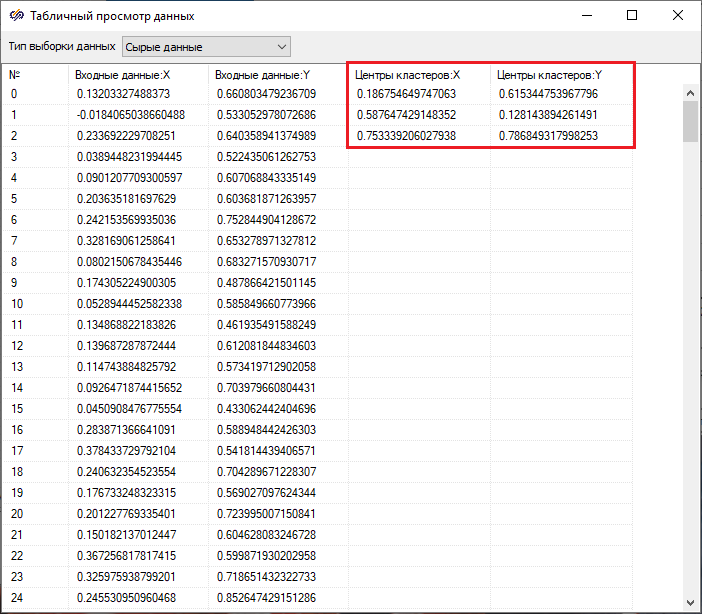
В результате сравнения полученных значений координат центров кластеров с заданным математическими ожиданиями координат центров, равными "(0.2, 0.6)", "(0.6, 0.15)" и "(0.75, 0.8)", установлено, что полученные значения практически совпадают с заданными.
Разработка модели для проведения кластерного анализа при отсутствии информации о количестве кластеров
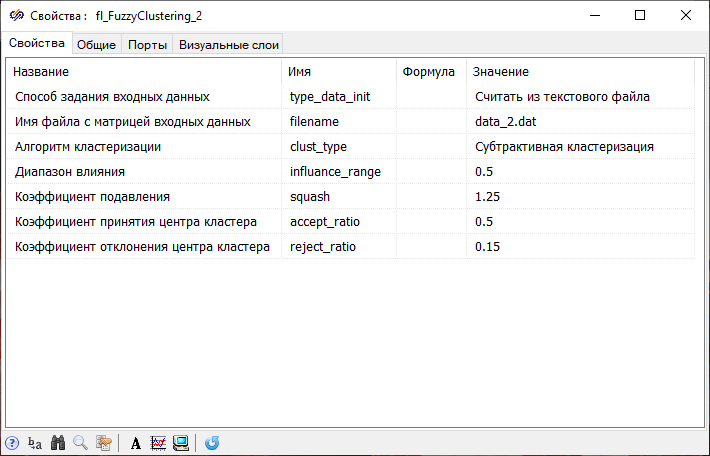
- Двойным нажатием левой кнопки мыши по блоку Нечеткая кластеризация с подписью "Кластеризация при отсутствии информации о количестве кластеров" вызвать окно График Y от X
- Открыть окно Свойства графика
- На вкладке Графики и оси в колонках "Ось X" и "Ось Y" задать значения свойств "Шаг сетки" равными "0.2"
- На вкладке Общие задать название графика как "Кластеризация при отсутствии информации о количестве кластеров"
- Сохранить изменения и закрыть окно нажатием кнопки Ok
Запуск моделирования и построение графиков
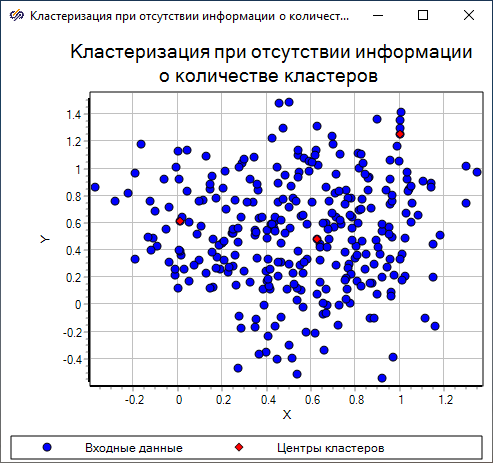
Полученная диаграмма рассеяния показывает, что при заданных значениях свойств количество кластеров, на которые следует разбить данное множество точек, равно "3".
Для исследования влияния параметра кластеризации "Диапазон влияния" на количество центров кластеров необходимо изменить значение данного свойства.
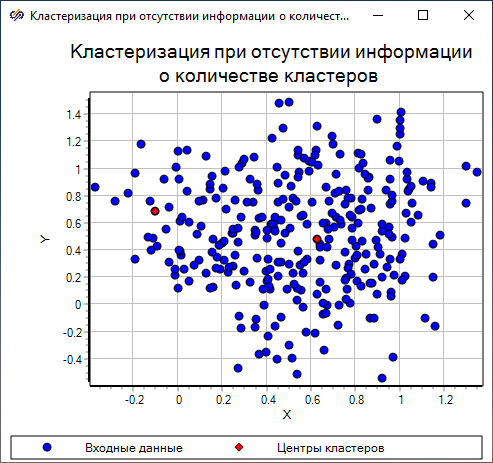
Полученная диаграмма рассеяния показывает, что при заданных значениях свойств количество кластеров, на которые следует разбить данное множество точек, равно "2".
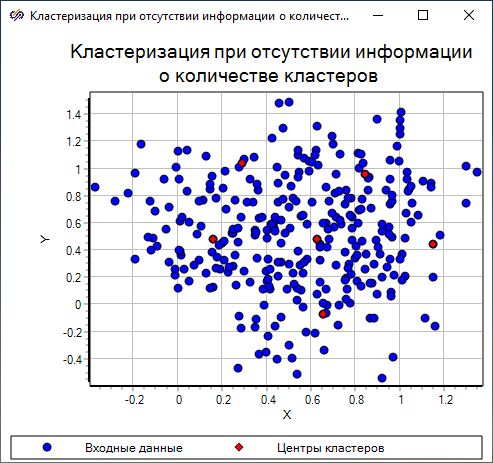
Полученная диаграмма рассеяния показывает, что при заданных значениях свойств количество кластеров, на которые следует разбить данное множество точек, равно "6".
Полученные диаграммы рассеяния (Рисунок 27, Рисунок 28, Рисунок 29) показывают, что при увеличении диапазона влияния количество кластеров, на которые следует разбить данное множество точек, уменьшается, а при уменьшении диапазона – количество кластеров увеличивается.
Перед следующим шагом, исходя из визуальной оценки найденного примерного расположения центров кластеров относительно точек множества входных данных, необходимо выбрать наиболее подходящее количество кластеров, на которое следует разбить сгенерированное множество.
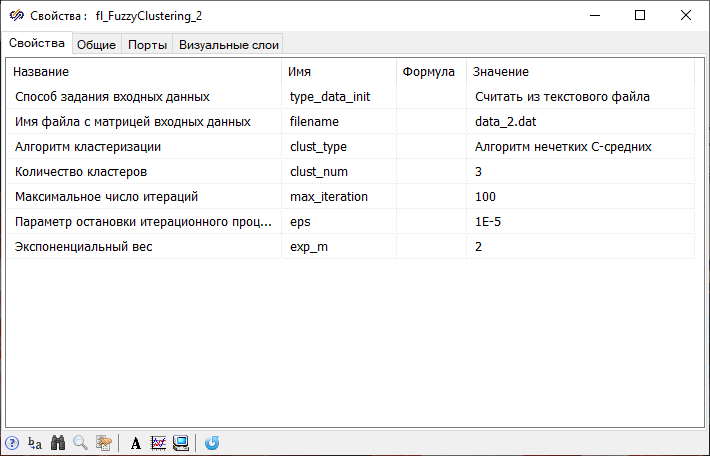
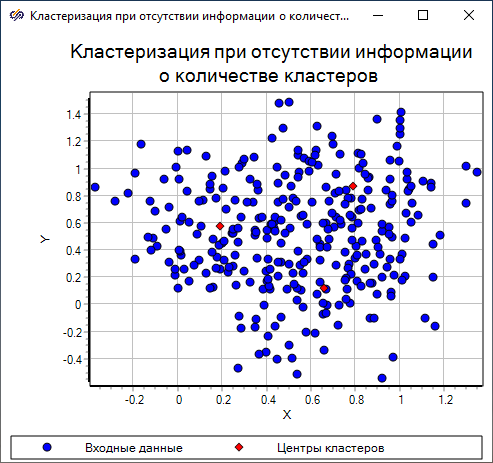
По полученной диаграмме рассеяния видно, что центры кластеров найдены правильно. Из сравнивая диаграмм, полученных в результате использования разных алгоритмов (Рисунок 27 и Рисунок 31), видно, что алгоритм нечетких С-средних более точно определяет центры кластеров. В свою очередь, алгоритм субтрактивной кластеризации менее точен, но для него не требуется информации о количестве кластеров.
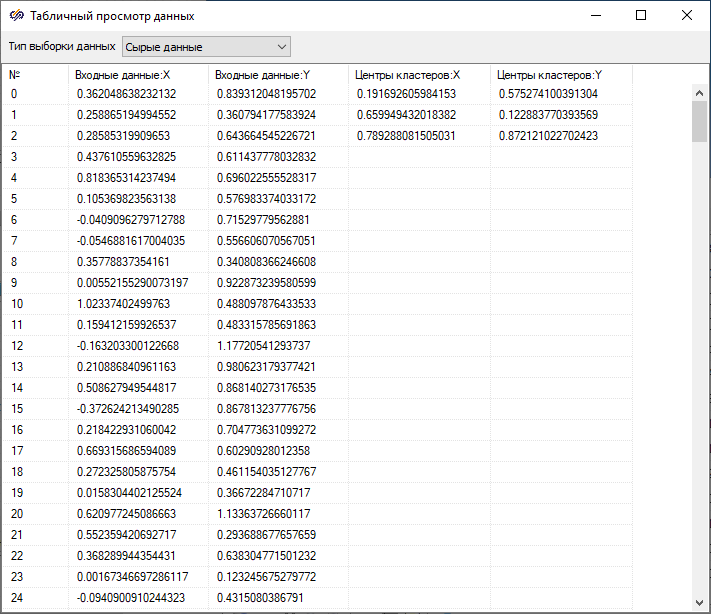
В результате сравнения полученных значений координат центров кластеров с заданным математическими ожиданиями координат центров, равными "(0.2, 0.6)", "(0.6, 0.15)" и "(0.75, 0.8)", установлено, что найденные значения практически совпадают с заданными, а отклонение обусловлено случайностью выборок и большим разбросом точек относительно центров кластеризации.
Заключение
В ходе данной лабораторной работы была разработана модель для генерации случайных выборок с заданными математическими ожиданиями и среднеквадратическими отклонениями, построены диаграммы рассеяния для сгенерированных выборок и разработана модель для проведения кластерного анализа. В результате моделирования были найдены центры кластеров сгенерированных выборок для двух случаев – при наличии и при отсутствии возможности оценить количество кластеров по диаграмме рассеяния.